 EN
EN


什么是 AI 推理?
AI 推理是人工智能领域中,将训练好的模型应用于实际数据分析和决策的过程。通过输入图像、文本、音频等数据,模型能够生成相应的结果,如分类、预测或识别。AI 推理广泛应用于人脸识别、语音助手、内容推荐等领域,为各种智能应用提供实时或近实时的分析支持。
AI 时代对推理提出了哪些要求?

高效能计算能力
- 算力需求:大模型的推理通常需要高性能计算硬件支持,尤其是针对深度学习的专用加速器。
- 低延迟:推理必须足够快速,以满足实时应用(如对话、搜索引擎等)的需求。
- 大规模并行处理:需要支持模型的分布式推理,充分利用多设备的计算资源。
内存与带宽优化
- 内存占用优化:大模型参数量庞大,对显存和内存提出极高要求。以 Llama 3.1 70B 模型为例,Hugging Face 预估支持其 FP16 精度的推理约需要 140GB 的内存。
- 高带宽支持:模型推理过程涉及大量的矩阵乘法和数据访问,高带宽存储和通信成为瓶颈。

模型压缩与优化技术
- 权重量化:通过将浮点数精度降低为 INT8、FP16 等格式,降低计算和存储需求。
- 模型蒸馏:通过将大模型知识迁移到小模型中,减少推理所需资源。
- 剪枝:通过删除冗余参数,减少模型复杂性。

灵活性与可扩展性
- 动态推理:支持动态长度输入输出(如文本生成任务)和自适应计算资源分配。
- 多任务处理:大模型通常需要支持多种任务类型的推理,如语言生成、图像识别等。
软硬一体的 AI 推理解决方案
针对当前复杂多变的技术挑战,摩尔线程提供了业内领先的软硬一体化 AI 推理解决方案,全面覆盖从云端到边缘的多样化应用场景,助力企业和个人高效应对各种需求。
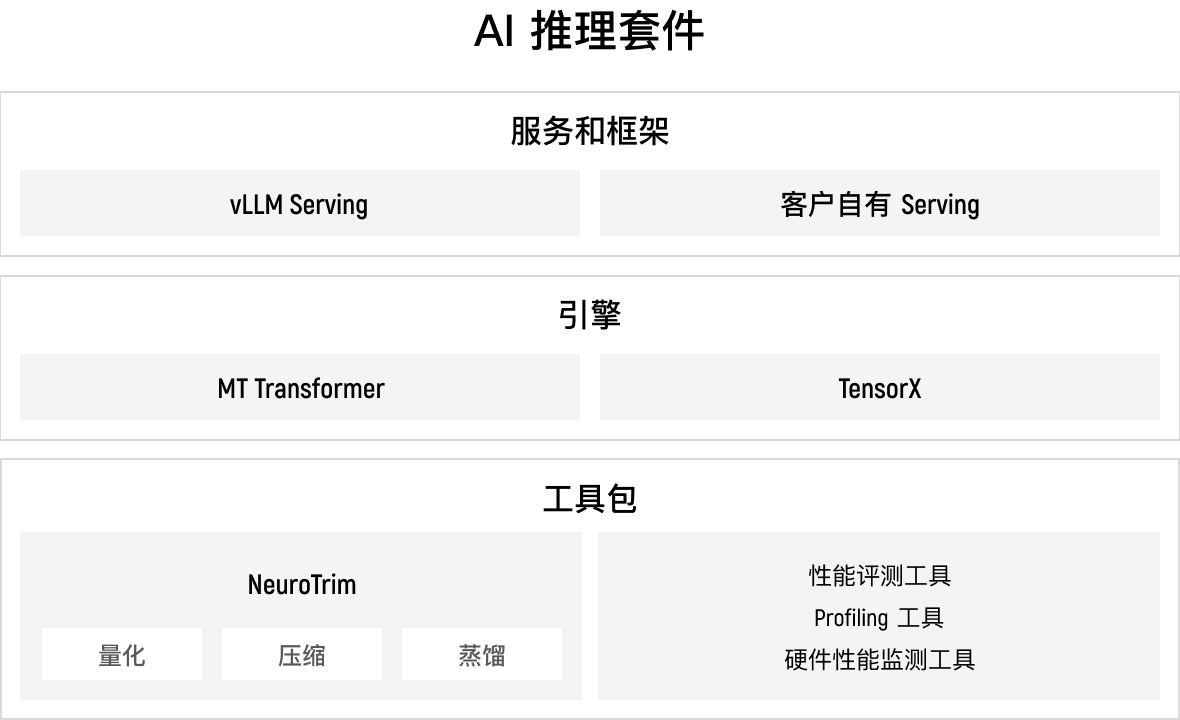
软件
在软件层面,摩尔线程的 AI 推理套件(KUAE Inference Suite)是专为满足生产级 AI 推理需求而设计的全方位软件包,其中包括了追求极致性能的大模型推理引擎 MT Transformer,以及覆盖丰富、性能优异的传统模型推理引擎 Tensor X,同时还提供了一系列量化、监测、Profiling 等推理常用的软件工具,为用户带来全面而高效的软件解决方案。
了解 KUAE Inference Suite
了解 KUAE Inference Suite
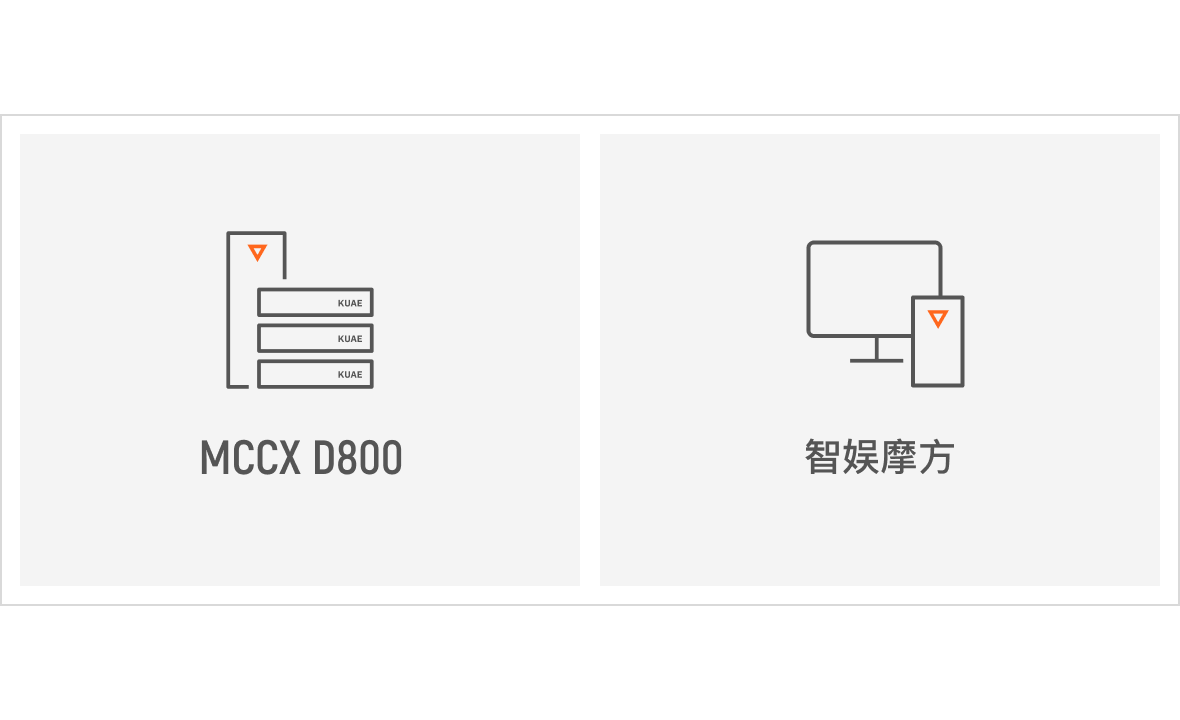
硬件
在硬件层面,摩尔线程推出了面向万卡智算集群的 AI 大模型训推一体机 MCCX D800,凭借其强大的算力,为云端大规模推理任务提供坚实保障。同时,端侧硬件产品以其高能效、低功耗和小型化的优势,可以为边缘场景的实时推理和本地化处理提供有力支持。
了解 MCCX D800 X1 了解智娱摩方
了解 MCCX D800 X1 了解智娱摩方
应用场景

数字孪生
AI 推理在数字孪生领域可以快速实现虚拟与现实世界的同步,通过实时数据分析与仿真,精确预测物理对象的运行状态与未来行为。这使得企业能够进行智能决策、优化生产流程,并提升系统维护效率,从而降低成本并提高整体生产力。

内容生成
借助 AI 推理,内容生成变得更加高效与智能化,能够生成高质量的图像、文本、音频和视频内容。AI 模型能够理解用户需求,自动创作符合特定风格和主题的内容,广泛应用于广告设计、影视制作、游戏开发等领域,释放人类创意潜力。

聊天机器人
推理驱动的 AI 聊天机器人具备强大的自然语言理解与生成能力,能够与用户进行流畅对话,快速提供信息和解决方案。这不仅提升了用户体验,还在客户服务、教育咨询和商业沟通中起到关键作用,大大提高了工作效率。

智能座舱
在智能座舱中,AI 推理实现了人机交互的智能化与个性化。通过语音识别、视觉分析等技术,AI 能够理解驾驶员的指令并提供导航、娱乐和安全预警功能,为驾驶体验带来便利与安全性,助力智能出行的未来发展。
医疗诊断
AI 推理在医疗诊断领域展现出精准高效的能力,能够快速分析海量医学影像与临床数据,辅助医生做出准确的诊断。AI 还能识别早期疾病迹象,提供个性化治疗方案,从而提升医疗服务质量,挽救更多患者的生命。





